
برای تقویت زبان انگلیسی مخصوصا تلفظ،دوستان پیشنهاد میکردن که سخنرانی افراد مشهور رو گوش کنم .از بین سخنرانی های که موجوده و توصیه میشد،سخنرانی های باراک اوباما بود.
سایتی وجود داره به نام americanrhetoric که یک صفحه داره مخصوص اقای اوباما که میتونید تمام سخنرانی هاشون رو از ابتدا به صورت فایل صوتی و به همراه متن سخنرانی به صورت pdf دانلود کنید.چیزی حدود ۴۵۰ تا سخرانی.
تصمیم گرفتم تمام سخنرانی های اقای اوباما رو دانلود کنم اما قاعدتا نمیشه که برای هرکدوم از سخنرانیهاش پوشه ساخت و دونه دونه دانلود کرد و ریخت توی پوشه . باید برنامهای مینوشتم که بیاد دانلود کنه و بریزه توی پوشههایی مشخص و مرتب کنه.
در ابتدا باید لینک های دانلود رو از صفحات وب میکشدم بیرون که برای اینکار از phantomjs استفاده کردم.
phantomjs در اصل یک مرورگر هست بدون المان های گرافیکی یعنی میتونید داخل خط فرمان استفاده کنید ازش. phantomjs رو نصب میکنیم روی اوبونتو
sudo apt-get install phantomjs
من از phantomjs استفاده کردم برای دریافت لینک ها و برای دانلود از node استفاده کردم. چون میخواستم اول لینکهای دانلود رو ذخیره کنم توی یک فایل json و بعد از داخل فایل json لینک هارو بخونم و دانلود کنم. خلاصه شما میتونید با فانتوم هم دانلود کنید.
در ابتدا یک فایل میسازم برای گرفتن لینک به نام getlinks.js و کدهای زیر رو داخلش کپی میکنم.
اول ماژول phantomjs,webpage رو فراخوانی میکنم و همین طور fs برای ریختن اطلاعات درون فایل json.
یک سری توضیحات رو درون کدها میدم .
"use strict";
let page = require('webpage').create(),
fs = require('fs');
page.open("http://www.americanrhetoric.com/barackobamaspeeches.htm", function(status) {
// صفحه مورد نظر رو بازش میکنم
if (status === "success") {
// وضعیتش رو چک میکنم که بدون ارور باشه و اگر شامل ارور باشه از phantom خارج بشیم.
page.includeJs("http://ajax.googleapis.com/ajax/libs/jquery/3.1.0/jquery.min.js", function() {
// چون صفحه مورد نظر جیکوئری نداره فایل جیکوئری رو اضافه میکنم بهش
let linkMp3Pdf=page.evaluate(function() {
// evaluate
// یک فانکشن هست که میشه یک سری ورودی بهش داد و یک سری خروجی از صفحه گرفت برای خودمون .
let arr=[];
$("#AutoNumber1 tbody tr:nth-child(n+3)").each(function(index,value){
let date = $(this).children().eq(0).text().replace(/(\r\n\t|\n|\r|\t)/gm,"").substring(6) || "";
let titleSpeech = $(this).children().eq(1).text().replace(/(\r\n\t|\n|\r|\t|[0-9]|\/)/gm,"").substring(6) || "";
let getLinkMp3 = $(this).children().eq(2).find("a").attr('href') || " ";
let getLinkPdf = $(this).children().eq(3).find("a").attr('href') || " ";
let obj = {"date":date,"titlespeech":titleSpeech,"getlinkmp3":getLinkMp3,"getlinkpdf":getLinkPdf};
arr.push(obj);
});
return arr;
});
let json= JSON.stringify(linkMp3Pdf);
fs.write("links.json",json,"w");
phantom.exit(0);
});
} else {
phantom.exit(1);
}
});
داخل evaluate ما لینک ها رو میریزیم توی یک آرایه بعد برمیگردونیمشون.
در ابتدا باید داخل کدهای صفحه بگردیم که بتونیم لینک هارو دربیاریم . با Inspect elementبه یک تیبل با id:AutoNumber1 میرسیم که تمام لینک ها داخل این قسمت هست.
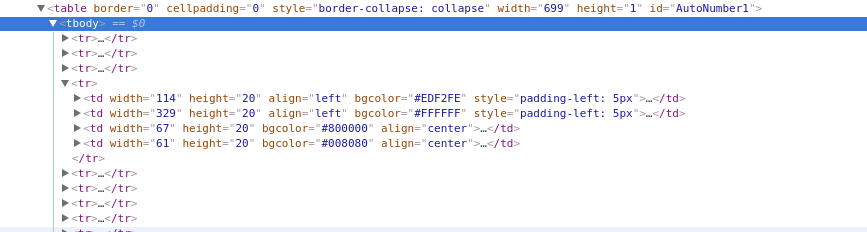
طبق عکس هر tr شامل لینک دانلود و به همراه تاریخ و عنوان سخنرانی هست .اما مشکلی که هست اینه که tr اول و دوم رو ما نمیخوایم . پس برای اینکه از تگ tr سوم اطلاعات رو بکشیم بیرون از nth-child استفاده میکنیم .تا اینجای کار همه ردیف هارو داریم حالا باید اطلاعات رو از هر ردیف بکشیم بیرون.اطلاعات درون تگ td هستن .
$(this)
به ما تگهای tr رو میده.
$(this).children()
به ما تگهای td درون هر tr رو میده
$(this).children().eq(0)
مارو میرسونه به اولین تگ td درون tr
از replace برای حذف ‘\r\n\t’ که توی html برای رفتن به خط بعدی است، استفاده کردم و بعد از substring برای حذف ۶ تا فاصله ابتدایی استرینگ تاریخمون استفاده کردم .
بعضی سخنرانیها تاریخ یا لینک pdf و… نداشت از “” || استفاده کردم.
عنوان سخنرانی رو دریافت کردم و ‘\r\n\t’ رو هم حذف کردم. مشکل اونجایی بود که درون استرینگ عنوان نباید هیچ ‘/’ و همچنین در ابتدای اون عدد باشه. پس یکم replace رو تغییر دادم. ‘/’ هنگامی که میخواستیم دانلود کنیم و بریزیم توی یک ادرس مشخص مشکل ساز بود چون بعد کارکتر / به دنبال دایرکتوری میگشت که اصلا وجود نداشت و ارور میداد.
واسه گرفتن لینک های mp3 و pdf نیاز داشتم که درون td بگردم و تگ a رو پیدا کنم و بعد ‘href’ اون رو بکشم بیرون .
حالا یک ابجکت میسازم که توی هر تکرار محتوا بالا رو بریزم توی ابجکت و بعد ابجکت رو بریزم درون ارایه و return کنم.
در اخر هم این ارایه رو میریزیم درون فایل jsonی به نام links که قبلا دستی ساخته بودیم .
و توی ترمینال phantomjs getlinks.js رو اجرا میکنم و صبر میکنم که اطلاعات رو بریزه توی جیسان(json)
تا اینجای کار من لینکها رو گرفتم و حالا میخوام دانلودشون کنم . روش های زیادی برای دانلود هست اما خب هیچ چیز بهتر از aria2c نمیشه :))
هم میشه تعداد کانکشن تعریف کرد -x و هم میشه کاری کرد که اگه فایل قبلا دانلود شده دوباره دانلود نکنه حتی با یک اسم دیگه،برای وقتایی که مثلا برق قطع میشه و میخواین دوباره از اول اسکریپت رو ران کنید جواب میده. continue=true
ماژول های مورد نیاز رو فراخونی میکنیم . متغیرهایی که میخوایم رو هم تعریف میکنیم.همین ابتدا بگم کهshelljs/global باshelljs یک فرقی داره خودتون تحیقیق کنید میاد دستتون.واینکه کارش این هست که میشه یک سری دستور سیستمی توی کدهامون ران کرد . مثل همین aria2c که نیاز داریم وباید نصبش کنید . داخل ترمینال کد زیر رو بزنید تا shelljs نصب بشه:
npm install shelljs -g
ادامه بعضی توضیحات رو داخل کدها میدم.
"use strict";
let fs = require('fs'),
dir = './download/';
require('shelljs/global');
// فایل جیسان رو میخونیم
let obj = JSON.parse(fs.readFileSync('links.json', 'utf8'));
// با مپ ابجکتهای جیسان رو میخونیم
obj.map(function(items){
// توی این قسمت چک میکنیم اگر پوشه مورد نظر از قبل وجود داره رو نسازه
if (!fs.existsSync(dir+items.date.replace(/ /g,"_").substr(-4)+items.titlespeach.replace(/ /g,"_") )){
// من دوست داشتم نام پوشه شامل سال سخنرانی و بعدش عنوان سخنرانی باشه و فاصله هارو تبدیل کردم به underline
fs.mkdirSync(dir+items.date.replace(/ /g,"_").substr(-4)+items.titlepeach.replace(/ /g,"_"));
}
// شروع به دانلود میکنیم
// -d برای انتقال به دایرکتوری مورد نظر هست
// res1 برای پاسخی که دریافت میکنیم تا چک کنیم اگر ارور داریم برامون توی کنسول چاپ کنه
console.log("downloading start");
let res1= exec("aria2c -x 10 -k 1M -s 10 --continue=true " + "http://www.americanrhetoric.com/"+items.getlinkmp3+" -d "+dir+items.date.replace(/ /g,"_").substr(-4)+items.titlespeach.replace(/ /g,"_"))
let res2= exec("aria2c -x 10 -k 1M -s 10 --continue=true " + "http://www.americanrhetoric.com/"+items.getlinkpdf+" -d "+dir+items.date.replace(/ /g,"_").substr(-4)+items.titlespeach.replace(/ /g,"_"))
if ( res1.code !== 0 || res2.code !==0) {
console.log("error");
}
});
در اخر هم برای دانلود توی ترمینال دستور زیر رو میزنیم .
node aria.js
حالا شما میتونید یکم خلاقیت به خرج بدین و تاریخ رو فیلتر کنید مثلا سخنرانی های ۲۰۱۵ به بعد رو بریزید توی آرایه و حتی سخنرانیهایی که کلمه ایران داره رو فیلتر کنید. ریش و قیچی دست شماست.حتی میتونید صفحات دیگر سخنرانها رو هم دانلود کنید.ویا حتی خیلی راحت میتونید لینک یوتیوب هر سخنرانی رو هم داخل صفحه مربوطه بگیرید و با استفاده از سایت های واسط دانلود از یوتیوب، لینک دانلود رو بگیرید و فایل ویدیویی سخنرانی رو هم دانلود کنید.کلیدهای کیبرد زیر دست شماست و منتظر شما هستند :))